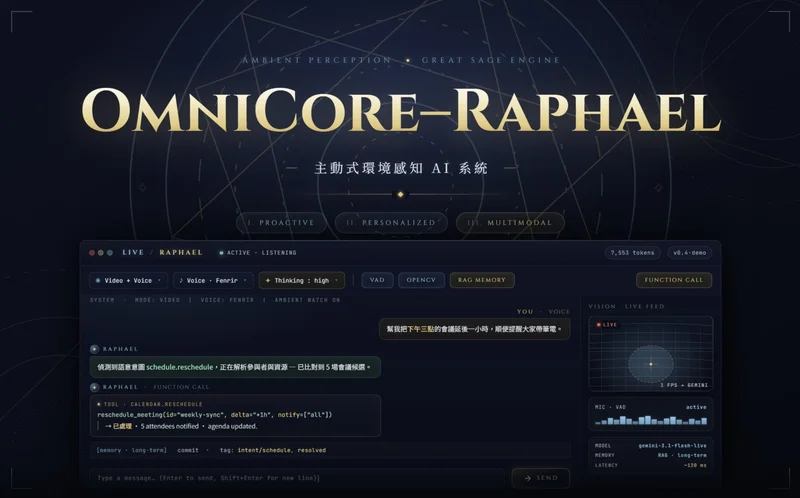
OmniCore-Raphael
主動式環境感知 AI 系統
by wayne-yang
一個主動式環境感知 AI 系統,透過麥克風與鏡頭持續感知周遭,自主判斷是否值得開口——不需要喚醒、等待指令。
OmniCore – Raphael
主動式環境感知 AI 系統
大多數 AI 在等待你開口。Raphael 不一樣——它一直在看,一直在聽,自己決定什麼時候值得說話。
動機
現在的 AI 已經很強,但它們本質上都是被動的:沒有指令就沒有動作。
《關於我轉生變成史萊姆這檔事》裡的智慧之王 Raphael 給了我們另一種想像——一個持續運作在背景、在你需要的當下主動提出建議、甚至直接完成任務的存在。它不需要被召喚,因為它從未離開。
OmniCore – Raphael 是這個想像的實作嘗試:一個以環境感知為觸發源的 AI 系統,不需要喚醒詞,不需要等待提問。
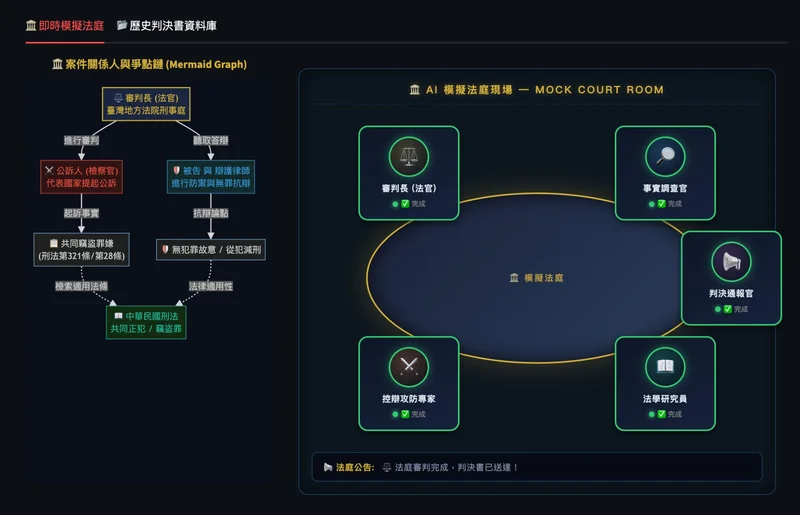
系統架構
麥克風 ──────────────────────────────────────────────┐
▼
鏡頭 ──── perception.py ──── mic_vad.py ──── gemini_session.py ──── audio_player.py
(視覺前處理) (音訊 VAD) (推論 + 決策) (語音輸出)
│
qdrant_store.py
(向量記憶儲存)
系統分為四層:
感知層(Perception Layer)
core/perception.py
- 透過筆電鏡頭定時擷取畫面,並在偵測到場景變化時主動觸發
- 使用 OpenCV 進行物件偵測、動態分析、環境變化比對
- 過濾靜態畫面,只有有意義的變化才往下傳
輸入處理層(Input Processing Layer)
core/mic_vad.py
- 即時麥克風串流,搭配 VAD(語音活動偵測)過濾靜音與雜訊
- 只有偵測到有效語音片段才觸發後續處理
- 避免系統對環境噪音做出無意義的反應
模型處理層(Model Layer)
core/gemini_session.py
- 整合來自感知層與記憶層的資訊,透過 Gemini Live API 進行推論
- 模型自主判斷是否值得回應:可以選擇語音回覆、執行 function call,或保持沉默
- 系統預設沉默——只有真正值得說的才開口
記憶層(Memory Layer)
memory/qdrant_store.py
- 使用 Qdrant 向量資料庫儲存對話與事件記憶
- 以 RAG(檢索增強生成)架構在推論時調用相關記憶
- 分長短期儲存,依重要性自動歸檔,避免記憶無限膨脹
Demo 功能展示
1. 環境感知與自主判斷
系統持續從鏡頭擷取畫面,透過 OpenCV frame diff 偵測場景變化。當變化超過閾值,感知層將事件送入推論流程,由 Gemini 自主決定是否值得開口。
# perception.py 核心邏輯示意
diff = cv2.absdiff(prev_frame, curr_frame)
change_score = diff.mean()
if change_score > PERCEPTION_THRESHOLD:
vision_queue.put({"frame": curr_frame, "reason": "scene_change"})
2. 沉默優先
系統預設不說話。Gemini 收到視覺或音訊事件後,會先判斷這個事件是否值得打擾使用者——大多數時候它選擇繼續觀察。
這是 Raphael 和一般語音助理最大的差異:它不會因為聽到聲音就回應,也不會因為有人在就說話。
3. Function Call(開發中)
core/tools.py
設計上,Raphael 不只是說話——它可以直接完成任務。模型推論後可以發出 function call,讓系統執行查詢、計算、或寫入記憶等操作,不需要人工介入。
實機展示案例:將球從明道樓拋出飛過樹梢所需的力——Raphael 觀察到場景後,主動進行物理估算並給出建議。某同學參考其建議後成功完成拋球。
程式碼結構
omnicore-raphael/
├── app.py # 主入口,啟動所有層
├── requirements.txt
├── core/
│ ├── config.py # 全域設定(閾值、API key、裝置選擇)
│ ├── perception.py # 視覺感知:OpenCV frame diff + 事件佇列
│ ├── mic_vad.py # 音訊輸入:即時串流 + VAD 過濾
│ ├── gemini_session.py # Gemini Live 會話管理:推論 + 決策
│ ├── audio_player.py # 語音輸出播放
│ └── tools.py # Function call 工具定義(開發中)
└── memory/
└── qdrant_store.py # 向量記憶:Qdrant + RAG 架構
技術選型說明
| 元件 | 選擇 | 原因 |
|---|---|---|
| 推論核心 | Gemini Live API | 支援即時音訊串流,內建 ASR + TTS |
| 視覺前處理 | OpenCV | 輕量,適合即時 frame diff 與物件偵測 |
| 音訊前處理 | VAD | 過濾靜音,降低無效觸發率 |
| 向量記憶 | Qdrant | 本地部署,低延遲,支援語意搜尋 |
| 語言 | Python 3.12 | 生態系完整,AI 套件支援最佳 |
未來展望
目前版本是以筆電為載體的 demo,核心引擎已驗證可行。下一階段目標:
01 — 本地前處理
將感知層與記憶層移至本地運算,不依賴雲端 API,保護隱私並消除 API 費用。
02 — 完整記憶系統
強化 RAG 架構,讓 Raphael 能跨對話記住使用者習慣、偏好與歷史事件,達到真正的個人化。
03 — 穿戴裝置整合
脫離筆電,整合至隨身裝置(穿戴式鏡頭 + 輕量運算單元),讓 Raphael 真正進入真實生活。
04 — 開源主動性引擎
將環境感知觸發的核心架構抽出為獨立模組,以 pip 套件形式開放給開發者社群使用。